|
A Large-Scale Foundation Model for Advancing Science: AuroraGPT
The highly collaborative AuroraGPT project leverages DOE supercomputing resources to develop and enhance understanding of powerful foundation models (FMs)— such as large language models (LLMs)—for science. In creating FMs for science—while developing underlying capabilities, tools and workflows, data resources, and other processes and artifacts—Argonne aims to significantly improve how science is conducted, by fostering a deeper integration of AI capabilities into research workflows. To this end, Argonne’s AuroraGPT project is creating and evaluating a series of increasingly powerful FMs, each with more parameters and/or trained on more data than its predecessors, designed to assist researchers in making more informed and efficient discoveries. The AuroraGPT research program focuses on producing this sequence of models while ensuring that each provides scientifically useful capabilities as well as scientific and computational performance knowledge to guide the design of the next model in the sequence
Challenge
The main tasks in the project include collecting and refining large-scale scientific datasets; building models at 8 billion to 400 billion or more parameter scales using general texts, code, and specific scientific data, and evaluating their performance on the Aurora and Polaris supercomputers; refining the models for deployment and introducing post-processing techniques such as instruct tuning and reinforcement learning for aligned chat-based interfaces; and evaluating the effectiveness of the models on scientific tasks.
Pretraining of AuroraGPT models has accounted for the bulk of the project’s compute resources. For each model, the developers aim to train some 2 trillion tokens, requiring many extensive, large-scale runs on Aurora. Initially, the developers found that the processing time necessary to establish indexing function for 2 trillion tokens was approximately 1 hour. Improvement of training performance has therefore been priority. The developers maintain a GitHub repository, Megatron DeepSpeed, which can train LLMs efficiently at scale on Aurora and Polaris. It has also been important to create new architecture-agnostic tools for LLMs and to adapt existing LLM tools for architecture agnosticism.
Performance Results
After debugging and implementing certain logic enhancements, the developers successfully reduced preprocessing time from approximately 1 hour to 2 minutes. This vastly improved both the AuroraGPT code and the developers’ ability to improve the code. Considerable effort has been put into making checkpoints convertible between the AuroraGPT software stack frameworks, particularly Megatron-DeepSpeed and Hugging Face.
The developers have successfully trained a model on 2 trillion tokens. After adapting the Meta-created LLM Llama for use on Aurora—involving the modification of the number of model layers and their sizes—the developers determined which data set to train it on and then optimized the implementation to get as close as possible to 100 percent utilization of compute resources. Initial training runs of the models helped the team identify instabilities to overcome. With the Llama LLM running smoothly, the developers were then able train it on 2 trillion tokens, effectively creating a ready, pretrained model.
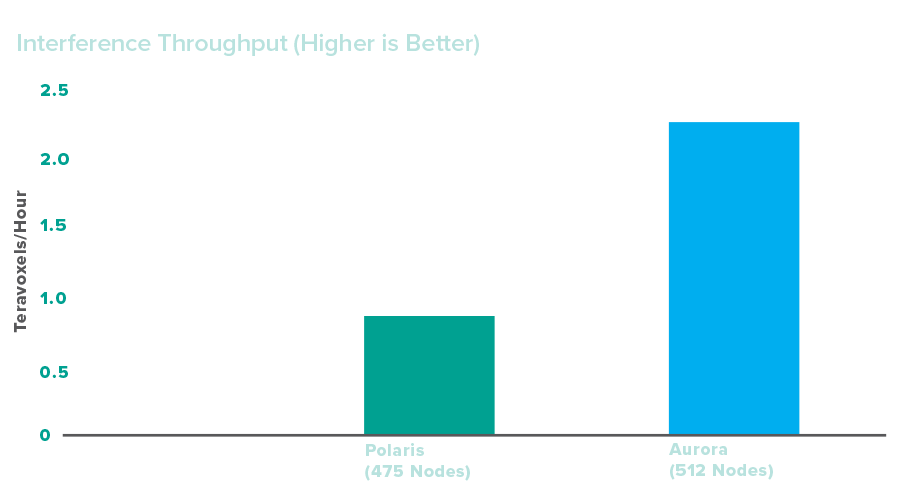
Impact
AuroraGPT represents a transformative opportunity to leverage AI for scientific discovery, potentially redefining problem-solving across various domains critical to the DOE’s mission. AuroraGPT will enable Aurora users to both train LLMs from scratch and finetune existing models. One pretrained model—trained on 2 trillion tokens—is already complete, providing Aurora users with a framework for deploying off-the-shelf LLMs for science campaigns and helping accelerate the pace of research while expanding the technology’s accessibility and deepening AI implementation in workflows.